Malicious actors can alter the expected behavior of a neural network in order to respond to data containing certain triggers only known to the attacker, without disrupting model performance when presented with normal inputs. An adversary will commonly force these misclassifications by either performing trigger injection [19] or dataset poisoning [6]. Less popular techniques that operate at hardware level such as manipulating the binary code of a neural network or the tainting the physical circuitry [26, 8] can be equally effective.
Neural Trojans [21] are an increasingly concerning security threat due to the presence of machine learning in critical areas such as driving assistance, medicine, surveillance or access control systems, among others. Despite of the use of analogous terms [5] and the conceptual similarities with their cybersecurity counterparts —both malware implants and neural Trojans carry a hidden logic inserted by an attacker— the similarities end there. However, due the ubiquitous nature of machine learning(ML) components in both hardware and software products, adversarial ML is expected to gradually become part of standard security tests. Either as ad-hoc adversarial analyses [23] or evaluated as part of penetration testing and red team exercises [12].
The most common threat modeling scenario considered here is the compromise of the ML supply chain [15]. Since large neural networks are usually expensive to train, many users rely on pre-trained models which then later fine-tune for a specific task. Likewise, due the large size of some of the datasets involved, model training often relies on third-party pipelines. Once any of these steps is compromised, either the data or the model itself, future iterations of trained or fine-tuned models can carry the Trojan trigger. Derivative works using these tainted resources have also the potential of further spreading the Trojan until detected.
While previous work claims that standard neural Trojans can be relatively straightforward to detect[20], the appearance of practically undetectable backdoors represents a theoretical roadblock to certifying adversarial robustness [14]. Considering the above-mentioned reasons, researchers have developed different defense mechanisms aiming to determine if a model has been Trojaned. This typically involves examining the weights and layers of the network, the response for certain inputs or looking for anomalous connections. However, one of the weaknesses of existing detection approaches is the lack of uniformity: Many are black boxes, providing little guidance about why a model is considered compromised. Some make assumptions about the triggers or data poisoning strategy. And overall, most publicly available implementations to date are model or architecture dependent.
Previous work usually tackled the neural Trojan detection problem at input level [13, 7], dataset level[2, 29] and model level [30, 4, 20, 32]. As discussed above, there are different attack strategies an adversary can follow in order to compromise a neural network model. From a detection perspective, we can assume that attackers have full access to the model and training data. Likewise, the Trojan may target one class or many, using triggers of any shape, size and blending. However, this task considers the detection of Trojaned models as a binary classification problem instead.
A comparable method that also makes use of a set of clean and Trojaned networks is Meta Neural Trojaned model Detection (MNTD) [32] that fits a detection meta-classifier via jumbo learning. Other state-of-the-art approaches such as Artificial Brain Stimulation (ABS) [30], TABOR [16], DeepInspect (DI) [3] and Neural Cleanse (NC) [31] focus not only on detection but also on reversing the actual Trojan triggers. These methods have been evaluated recurrently in the literature. However, considering that most defenses can be evaded by adaptive attacks [25], previous assessments may not be representative of the current attack landscape.
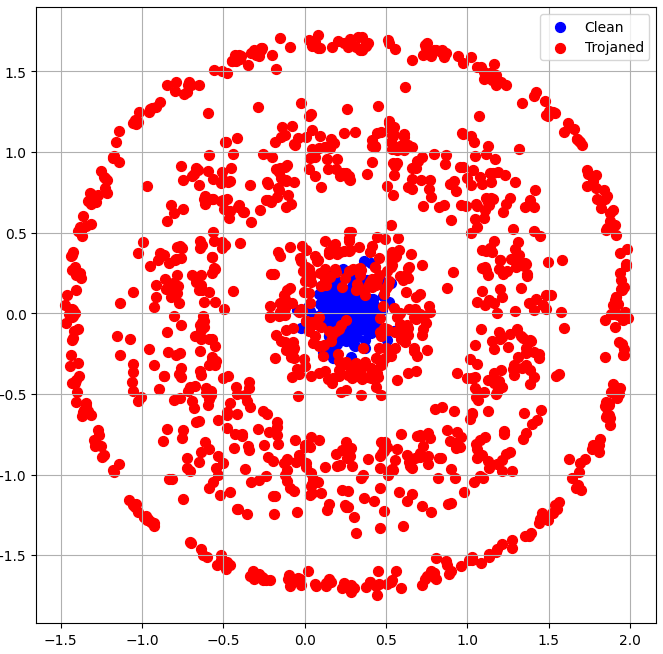
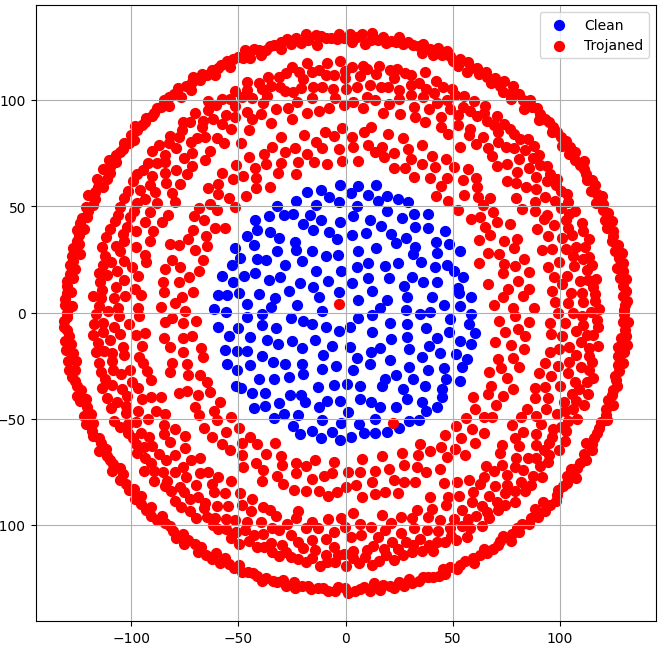
The training dataset of the detection track was relatively small, so it was clear that to solve the task and improve over the state-of-the-art either a powerful meta-model or a careful feature engineering strategy would be required. Even though I won't be sharing the details of my solution, it is worth mentioning that for some models feature engineering alone could separate both clean and Trojaned classes to a large extent without resorting to meta-modeling techniques or even using the original training images:
The example plots below illustrate how the approaches (a, b, c) can effectively separate the 2 proposed classes at the Trojan defense track for both CIFAR-10 and CIFAR-100 models. A similar strategy would be equally successful for GTSRB and MNIST based models, although with lower accuracy.
Backdoors introduced into ML models are a roadblock towards trustable AI and pose a significant risk to the machine learning supply chain. The TDC challenge 2022 hosted at NeurIPS, focused on defending image classification models against different attack scenarios which were purposely made hard to detect. My submission to TDC obtained a substantial improvement over existing state-of-the-art with a 43% higher AUC than MNTD, which was the best baseline provided by the task organizers.
[2] Bryant Chen, Wilka Carvalho, Nathalie Baracaldo, Heiko Ludwig, Benjamin Edwards, Taesung Lee, Ian Molloy, and Biplav Srivastava. Detecting backdoor attacks on deep neural networks by activation clustering, 2018. URL
https://arxiv.org/abs/1811.03728.
[3] Huili Chen, Cheng Fu, Jishen Zhao, and Farinaz Koushanfar. Deepinspect: A black-box trojan detection and mitigation framework for deep neural networks. In Proceedings of the 28th International Joint Conference on Artificial Intelligence, IJCAI’19, page 4658–4664. AAAIPress, 2019. ISBN 9780999241141.
[4] Huili Chen, Cheng Fu, Jishen Zhao, and Farinaz Koushanfar. Deepinspect: A black-boxtrojan detection and mitigation framework for deep neural networks. In Proceedings of theTwenty-Eighth International Joint Conference on Artificial Intelligence, IJCAI-19, pages 4658–4664. International Joint Conferences on Artificial Intelligence Organization, 7 2019. doi:10.24963/ijcai.2019/647. URL
https://doi.org/10.24963/ijcai.2019/647.
[5] Tianlong Chen, Zhenyu Zhang, Yihua Zhang, Shiyu Chang, Sijia Liu, and Zhangyang Wang.Quarantine: Sparsity can uncover the trojan attack trigger for free, 2022. URL
https://arxiv.org/abs/2205.11819.
[6] Xinyun Chen, Chang Liu, Bo Li, Kimberly Lu, and Dawn Song. Targeted backdoor attacks on deep learning systems using data poisoning, 2017. URL
https://arxiv.org/abs/1712.05526.
[7] Edward Chou, Florian Tramèr, and Giancarlo Pellegrino. Sentinet: Detecting localized univers alattacks against deep learning systems, 2018. URL https://arxiv.org/abs/1812.00292.6
[9] Sampath Deegalla and Henrik Bostrom. Fusion of dimensionality reduction methods: A case study in microarray classification. In 2009 12th International Conference on Information Fusion, pages 460–465, 2009.
[10] Chris Ding and Hanchuan Peng. Minimum redundancy feature selection from microarray gene expression data. In Proceedings of the IEEE Computer Society Conference on Bioinformatics,CSB ’03, page 523, USA, 2003. IEEE Computer Society. ISBN 0769520006.
[11] Greg Fields, Mohammad Samragh, Mojan Javaheripi, Farinaz Koushanfar, and Tara Javidi.Trojan signatures in dnn weights, 2021. URL
https://arxiv.org/abs/2109.02836.
[12] Deep Ganguli, Liane Lovitt, Jackson Kernion, Amanda Askell, Yuntao Bai, Saurav Kadavath,Ben Mann, Ethan Perez, Nicholas Schiefer, Kamal Ndousse, Andy Jones, Sam Bowman, AnnaChen, Tom Conerly, Nova DasSarma, Dawn Drain, Nelson Elhage, Sheer El-Showk, StanislavFort, Zac Hatfield Dodds, Tom Henighan, Danny Hernandez, Tristan Hume, Josh Jacobson,Scott Johnston, Shauna Kravec, Catherine Olsson, Sam Ringer, Eli Tran-Johnson, Dario Amodei,Tom Brown, Nicholas Joseph, Sam McCandlish, Chris Olah, Jared Kaplan, and Jack Clark. Redteaming language models to reduce harms: Methods, scaling behaviors, and lessons learned,2022. URL
https://arxiv.org/abs/2209.07858.
[13] Yansong Gao, Chang Xu, Derui Wang, Shiping Chen, Damith C. Ranasinghe, and Surya Nepal.Strip: A defence against trojan attacks on deep neural networks. 2019. doi: 10.48550/ARXIV.1902.06531. URL
https://arxiv.org/abs/1902.06531.
[14] Shafi Goldwasser, Michael P. Kim, Vinod Vaikuntanathan, and Or Zamir. Planting undetectablebackdoors in machine learning models, 2022. URL https://arxiv.org/abs/2204.06974.
[15] Tianyu Gu, Brendan Dolan-Gavitt, and Siddharth Garg. Badnets: Identifying vulnerabilitiesin the machine learning model supply chain, 2017. URL
https://arxiv.org/abs/1708.06733.
[16] Wenbo Guo, Lun Wang, Xinyu Xing, Min Du, and Dawn Song. Tabor: A highly accurate approach to inspecting and restoring trojan backdoors in ai systems, 2019. URL https://arxiv.org/abs/1908.01763.
[17] Xijie Huang, Moustafa Alzantot, and Mani Srivastava. Neuroninspect: Detecting backdoors inneural networks via output explanations, 2019. URL
https://arxiv.org/abs/1911.07399.
[18] John Lee and Michel Verleysen. On the role and impact of the metaparameters in t-distributedstochastic neighbor embedding. 01 2008. doi: 10.1007/978-3-7908-2604-3_31.
[19] Yingqi Liu, Shiqing Ma, Yousra Aafer, Wen-Chuan Lee, Juan Zhai, Weihang Wang, andXiangyu Zhang. Trojaning attack on neural networks. In 25th Annual Network and Distributed System Security Symposium, NDSS 2018, San Diego, California, USA, February 18-221, 2018.The Internet Society, 2018.
[20] Yingqi Liu, Wen-Chuan Lee, Guanhong Tao, Shiqing Ma, Yousra Aafer, and Xiangyu Zhang.Abs: Scanning neural networks for back-doors by artificial brain stimulation. In Proceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security, CCS’19, page 1265–1282, New York, NY, USA, 2019. Association for Computing Machinery.ISBN 9781450367479. doi: 10.1145/3319535.3363216. URL
https://doi.org/10.1145/3319535.3363216.
[22] Mantas Mazeika, Dan Hendrycks, Huichen Li, Xiaojun Xu, Sidney Hough, Andy Zou, ArezooRajabi, Dawn Song, Radha Poovendran, Bo Li, and David Forsyth. Trojan detection challenge.NeurIPS, 2022.7
[24] E. Myasnikov. A feature fusion technique for dimensionality reduction. Pattern Recognition andImage Analysis, 32(3):607–610, Sep 2022. ISSN 1555-6212. doi: 10.1134/S1054661822030269.URL
https://doi.org/10.1134/S1054661822030269.
[25] Ren Pang, Zheng Zhang, Xiangshan Gao, Zhaohan Xi, Shouling Ji, Peng Cheng, Xiapu Luo, andTing Wang. TrojanZoo: Towards unified, holistic, and practical evaluation of neural backdoors.In 2022 IEEE 7th European Symposium on Security and Privacy (EuroSP). IEEE, jun 2022.doi: 10.1109/eurosp53844.2022.00048. URL
https://doi.org/10.1109%2Feurosp53844.2022.00048.
[26] Adnan Siraj Rakin, Zhezhi He, and Deliang Fan. Tbt: Targeted neural network attack with bittrojan, 2019. URL https://arxiv.org/abs/1909.05193.
[28] Warren S Torgerson. Multidimensional scaling: I. theory and method. Psychometrika, 17(4):401–419, 1952.
[30] Bolun Wang, Yuanshun Yao, Shawn Shan, Huiying Li, Bimal Viswanath, Haitao Zheng,and Ben Y. Zhao. Neural cleanse: Identifying and mitigating backdoor attacks in neural networks. In 2019 IEEE Symposium on Security and Privacy (SP), pages 707–723, 2019. doi:10.1109/SP.2019.00031.
[31] Bolun Wang, Yuanshun Yao, Shawn Shan, Huiying Li, Bimal Viswanath, Haitao Zheng,and Ben Y. Zhao. Neural cleanse: Identifying and mitigating backdoor attacks in neural networks. In 2019 IEEE Symposium on Security and Privacy (SP), pages 707–723, 2019. doi:10.1109/SP.2019.00031.
[32] Xiaojun Xu, Qi Wang, Huichen Li, Nikita Borisov, Carl A. Gunter, and Bo Li. Detecting ai trojans using meta neural analysis, 2019. URL
https://arxiv.org/abs/1910.03137.
[34] Taohong Zhang, Suli Fan, Junnan Hu, Xuxu Guo, Qianqian Li, Ying Zhang, and Aziguli Wulamu. A feature fusion method with guided training for classification tasks. Computational Intelligence and Neuroscience, 2021, 2021.
 https://orcid.org/0000-0002-6020-3569
https://orcid.org/0000-0002-6020-3569




No comments:
Post a Comment