 https://orcid.org/0000-0002-6020-3569
https://orcid.org/0000-0002-6020-3569
The modern NLG landscape is plagued by two interlinked problems: On the one hand, our current neural models have a propensity to produce inaccurate but fluent outputs; on the other hand, our metrics are most apt at describing fluency, rather than correctness. This leads neural networks to “hallucinate”, e.g., produce fluent but incorrect outputs that we currently struggle to detect automatically. For many NLG applications, the correctness of an output is however mission-critical. For instance, producing a plausible-sounding translation that is inconsistent with the source text puts in jeopardy the usefulness of a machine translation pipeline. For this reason, SHROOM, a Shared-task on Hallucinations and Related Observable Overgeneration Mistakes aims to foster the growing interest in this topic in the community.
In this competition participants were asked to perform binary classification to identify cases of fluent overgeneration hallucinations in two different setups: model-aware and model-agnostic tracks. In order to do this, they had to detect grammatically sound outputs which contain incorrect or unsupported semantic information, inconsistent with the source input, with or without having access to the model that produced the output.
The evaluated approach using a simple linear combination of reference models ranked 3rd in the model-agnostic track with a 0.826 accuracy.
Related work

Source of Image 1: Survey of Hallucination in Natural Language Generation
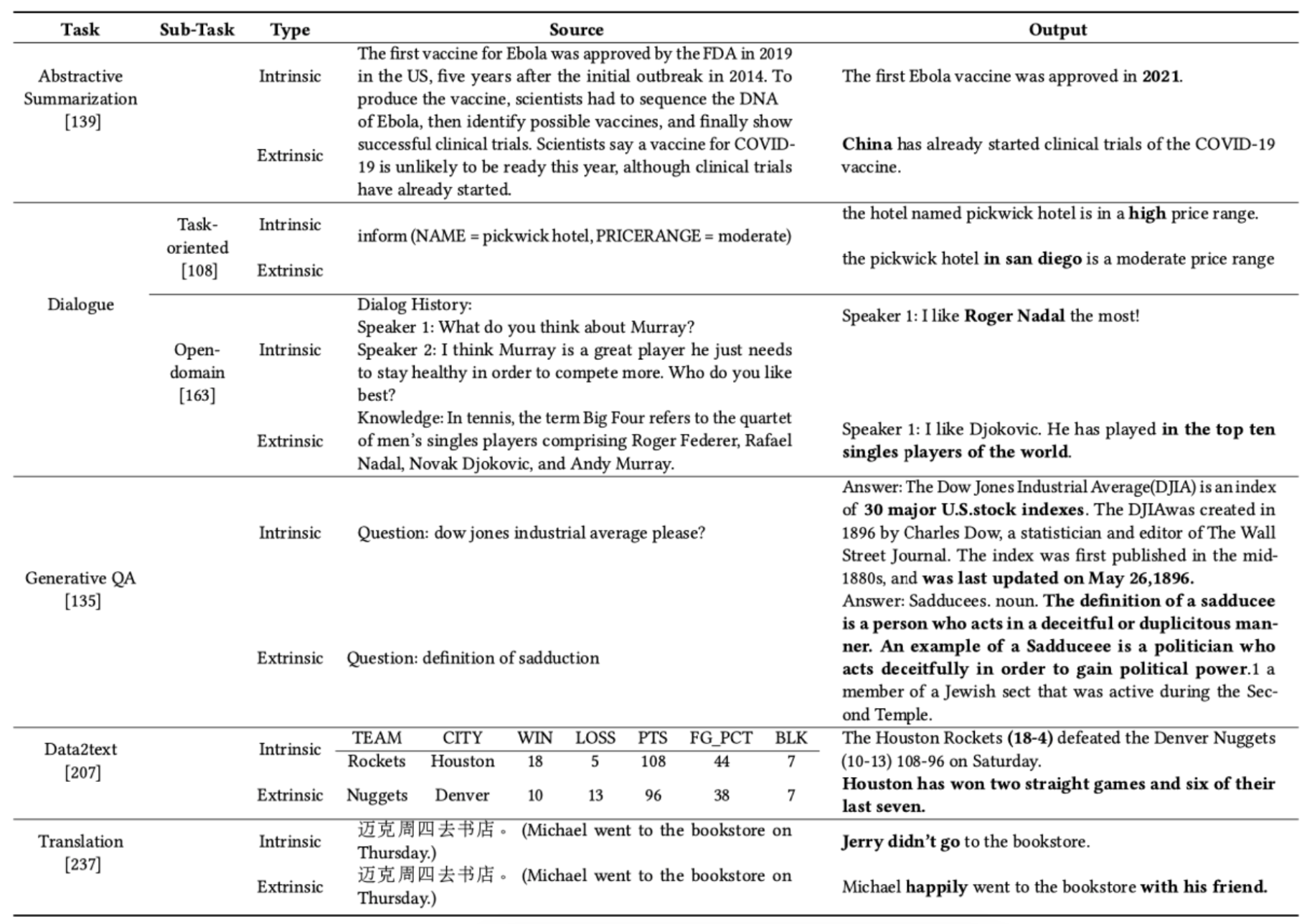
Approach
- COMET: Developed by Rei et al., COMET is a neural quality estimation metric that has been validated as a state-of-the-art reference-based method [Kocmi et al.].
- Vectara HHEM: an open source model created by Vectara, for detecting hallucinations in LLMs. It is particularly useful in the context of building retrieval-augmented-generation (RAG) applications where a set of facts is summarized by an LLM, but the model can also be used in other contexts.
- LaBSE: a measure evaluates the cosine similarity of the source and translation sentence embeddings [Feng et al.]. It's a dual-encoder approach that relies on pretrained transformers and is fine-tuned for translation ranking with an additive margin softmax loss. Two different features were extracted from this approach depending on the variables considered via cosine similarity:
- labse1: hypotesis VS target
- labse2: hypothesis VS source
- SelfCheckGPT QA (MQAG) [Manakul et al.] facilitates consistency assessment by creating multiple-choice questions that a separate answering system can answer for each passage. If the same questions are asked it's anticipated that the answering system will predict the same answers. The MQAG framework is constructed of three main components: a question-answer generation system (G1), a distractor generation system (G2), and an answering system (A). Two different features were extracted via this approach, one using GPT3.5 Turbo and another using GPT4.

Results
| # | User | Entries | Date of Last Entry | Team Name | Accuracy |
|---|---|---|---|---|---|
1 | liuwei | 14 | 01/30/24 | HIT_WL | 0.83067 (1) |
2 | bradleypallen | 5 | 01/31/24 | 0.82933 (2) | |
3 | amsqr | 23 | 01/30/24 | Alejandro Mosquera | 0.82600 (3) |
| 4 | ahoblitz | 28 | 01/31/24 | 0.82333 (4) | |
| 5 | zackchen | 10 | 01/31/24 | OPDAI | 0.82133 (5) |
| 6 | vasko | 2 | 02/01/24 | DeepPavlov | 0.82067 (6) |
| 7 | BruceW | 10 | 01/31/24 | 0.80000 (7) | |
| 8 | Piyush | 26 | 02/01/24 | AMEX_AI_Labs | 0.79933 (8) |
| 9 | Nemo | 11 | 01/31/24 | 0.79933 (8) | |
| 10 | konstantinkobs | 1 | 01/21/24 | Pollice Verso | 0.79667 (9) |
| 11 | yashkens | 3 | 02/01/24 | smurfcat | 0.79533 (10) |
| 12 | lmeribal | 14 | 02/01/24 | smurfcat | 0.79533 (10) |
| 13 | janpf | 15 | 01/25/24 | Pollice Verso | 0.79400 (11) |
| 14 | mmazarbeik | 6 | 01/31/24 | 0.79267 (12) | |
| 15 | refaat1731 | 1 | 01/31/24 | 0.79200 (13) | |
| 16 | ustc_xsong | 2 | 01/31/24 | 0.78533 (14) | |
| 17 | wutianqidx | 3 | 01/31/24 | 0.78067 (15) | |
| 18 | zhuming | 5 | 02/01/24 | 0.77333 (16) | |
| 19 | bond005 | 21 | 02/01/24 | SibNN | 0.77000 (17) |
| 20 | ronghao | 1 | 01/22/24 | UMUTeam | 0.76933 (18) |
| 21 | Nihed_B | 30 | 01/31/24 | 0.76133 (19) | |
| 22 | patanjali-b | 4 | 01/28/24 | 0.74867 (20) | |
| 23 | ioannaior | 13 | 01/30/24 | 0.74400 (21) | |
| 24 | daixiang | 1 | 01/27/24 | 0.73733 (22) | |
| 25 | gabor.recski | 4 | 01/31/24 | 0.73467 (23) | |
| 26 | Subin | 6 | 01/17/24 | 0.72800 (24) | |
| 27 | zahra_rahimi | 7 | 01/19/24 | HalluSafe | 0.72400 (25) |
| 28 | Natalia_Grigoriadou | 17 | 01/29/24 | 0.70867 (26) | |
| 29 | natalia65479693 | 5 | 01/29/24 | 0.70867 (26) | |
| 30 | LexieWei | 1 | 01/12/24 | 0.68800 (27) | |
| 31 | novice_r8 | 6 | 01/23/24 | Halu-NLP | 0.68667 (28) |
| 32 | PaulTrust | 2 | 01/20/24 | 0.68333 (29) | |
| 33 | AKA | 8 | 02/01/24 | CAISA | 0.67667 (30) |
| 34 | PooyaFallah | 10 | 01/31/24 | SLPL SHROOM | 0.65800 (31) |
| 35 | deema | 7 | 02/01/24 | 0.64600 (32) | |
| 36 | SergeyPetrakov | 35 | 02/01/24 | Skoltech | 0.63000 (33) |
| 37 | byun | 2 | 01/23/24 | Byun | 0.61667 (34) |
| 38 | SOHAN2004 | 7 | 01/31/24 | 0.61533 (35) | |
| 39 | Chinnag | 2 | 01/26/24 | ai_blues | 0.58733 (36) |
| 40 | felix.roth | 8 | 02/01/24 | 0.57400 (37) | |
| 41 | yash9439 | 9 | 01/24/24 | NootNoot | 0.51467 (38) |
| 42 | abhyudaysingh | 3 | 02/01/24 | 0.49800 (39) | |
| 43 | ptrust | 8 | 01/31/24 | 0.48933 (40) | |
| 44 | Yuan_Lu | 6 | 01/31/24 | 0.46067 (41) |
References
chrF++: words helping character n-grams [Popovic]
COMET: A neural framework for MT evaluation [Rei et al.]
Massively multilingual sentence embeddings for zero- shot cross-lingual transfer and beyond [Artetxe and Schwenk]Unsupervised cross-lingual representation learning at scale [Conneau et al.]
Xnli: Evaluating cross- lingual sentence representations [Conneau et al.]
Evaluating Factuality in Generation with Dependency-level Entailment [Goyal and Durrett]
QuestEval: Summarization Asks for Fact-based Evaluation [Scialom et al.]
SummEval: Re-evaluating Summarization Evaluation [Fabbri et al.]
SummaC: Re-visiting NLI- based models for inconsistency detection in summarization [Laban et al.]
No comments:
Post a Comment